多个回归模型结合的多目标优化
《An Ensemble Surrogate-Based Framework for Expensive Multiobjective Evolutionary Optimization》
说明:参考价值不大,整体思路太平,没有创新点,只是本着我已经读了所以也放上来而已的态度
摘要
是一个online的DDEA算法,主要是提出了一个集成模型的框架,这个框架可以辅助MOEA选择
总体框架
模型:ensemble surrogate framework(ESF)
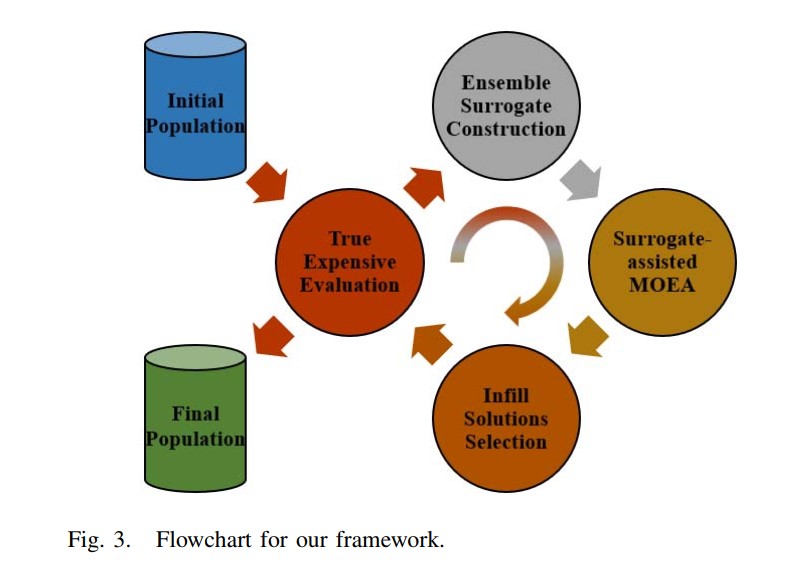
1、初始化
使用标准边界交叉法(NBI)生成一组参考向量;使用LHS采样生成N个训练样本点,形成初始种群P。
- DB:训练数据集
- :从模型里采样进行真实问题评估的样本数目
标准边界交叉法(nomal boundary intersection NBI)
对于一个M个目标的问题,在目标空间上每个目标假设被划分为H份,则有划分公式
在选定M和H之后可以得到一个各个目标的权重配比,构成每一个目标方向上的参考向量,这个方法也被用在MOEA/D和NSGA-Ⅲ中,用于求目标空间的均匀权重向量分布
2、进化循环
在进化循环开始之前,初始种群中所有的个体都需要用真实的函数进行评估,然后将评估过后的个体加入DB中。
3、集成模型的构建
集成模型分为一个全局的模型和K个子模型。
本文使用的是kriging模型,子模型的维度计算如下
其中r 任意在(0,1)之间。
why?
使用回归模型,维度越低,其拟合效果越好,因此几个子模型的变量维度减小,用于对全局模型的验证
训练模型
- 训练K个子模型:从决策向量中随机选择其中的个决策变量加入训练数据集中,进行训练
- 训练一个全局模型:使用DB进行训练
模型集成
将全部模型集成
模型的输出
其中,表示第i个子模型的输出,表示全局模型的输出.
c作为集成模型内的权重配比系数,需要满足以下条件:
- 初期DB的数据较少,子模型显然比全局模型的效果更好,需要权重较大
- 后期全局模型的效果会更好,所有后期GSM的系数应该更大
4、模型辅助的MOEA
在MOEA中,使用模型来代替适应度函数的估计,生成子代,更新种群,迭代t(prefixed)代
5、infill sampling
这是online-DDEA所特有的,可以在进化过程中,可以从新的种群中选的个体通过真实的目标函数评估后并入训练数据集,然后更新集成模型。
- 首先从中移除重复的解和被DB的解所支配的解
- 然后在所有的参考向量(参考向量组)中随机选择个形成参考向量组,依次计算选出的参考向量和种群中的所有参考向量的夹角的余弦值
-
- 对每一个参考向量,选出S中与其夹角最小的一个,将该个体并入种群P,进行真实目标函数的评估
ESF-NSGA-Ⅲ
参数设置
| 参数名称 | 数值大小 |
|---|---|
| 种群大小 | |
| 最大真实目标函数评估次数 | |
| 子模型的个数(K) | 2 |
| D表示问题的维数(决策变量的个数) |
 wechat
wechat alipay
alipay




