基于关系模型的超多目标优化算法
《Expensive Multiobjective Optimization by Relation Learning and Prediction》
摘要
使用了两两对比的比较模型,并非根据传统的支配关系建立样本对比较,而是依据MOEA/D中的PBI指标进行支配关系的标签建立和进行比较
创新点
1、使用了基于关系的分类模型,减少了回归模型的时间复杂度
2、对数据集进行了数据分割,使得训练样本标签分布基本是均匀的
3、使用多次模型结果综合判断,减少因为模型的预测错误而导致的判断错误
4、使用了基于径向过程的个体选择来保持多样性和收敛性
速看版本

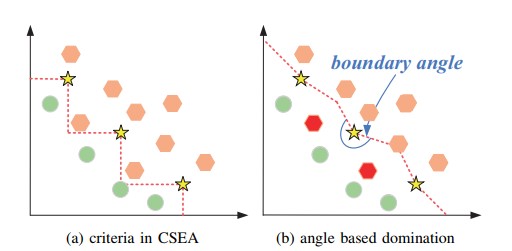
- 基本沿袭CSEA的基本思路,只是在模型和细节上有一些调整
- 使用径向过程选定参考解,详见CSEA
- 使用真实的目标函数与参考点集合依次进行PBI关系的对比,将种群分为nondominance和dominated,记作
- 分别在两个种群中选出点组成样本对,并根据所在的种群对该样本对打上标签[-1,+1,-0,+0]
- 使用所得的样本对训练分类模型
- 对原来的种群使用遗传方式产生后代新的个体,每个个体都需要与父代的个体形成四个样本对并用模型进行预测四次,四次的结果使用一个voting的得分计算该个体是非支配还是被支配的以决定是否要保留该个体
- 最后还是使用径向方式进行投影并进行环境选择
- 循环上述所有步骤,直到
框架
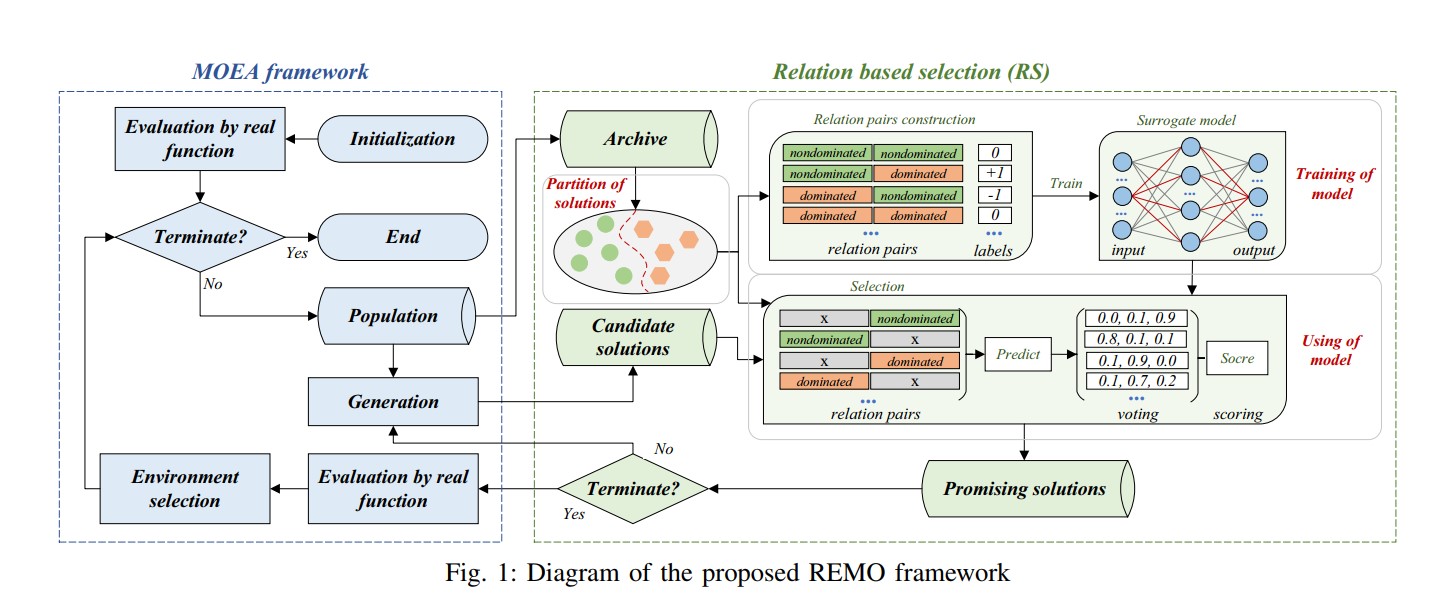
1、初始化
生成初始种群,使用LHS采样方式
2、更新参考解
使用与CSEA相同的径向方法得到k个参考解,将这些解作为数据分割的分类边界
3、数据分割
根据PBI方法将种群P以分类边界分割为被支配的,非支配的两个子种群
4、模型构建和训练
分别从两个子种群依次取出样本对(pairs),打上标签,作为输入训练分类模型
5、模型辅助选择
使用交叉,变异等方式产生子代,每一个新产生的解将会和依次和所有父代的个体均产生4个样本对,并使用模型根据四次的结果由voting方法计算出一个得分,选出promising solution
6、存档更新和环境选择
在5中选择出的解将会由真实的目标函数进行评估从而更新存档Arc,接着从存档中选择N个个体形成新的种群
7、停止
循环2、3、4、5、6直到
细节
1、数据分割
与CSEA中根据真实目标函数计算判断支配关系不同,这里使用的是PBI方法来判断一个解是不是非支配的,需要判断这个解的PBI值是否比与其夹角最小的一个参考点到理想点的距离小,即(1)式
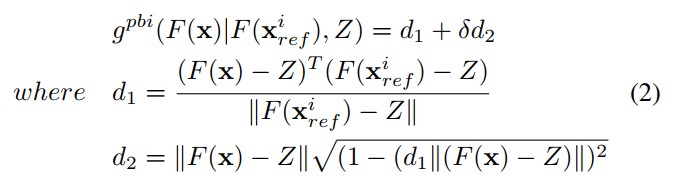
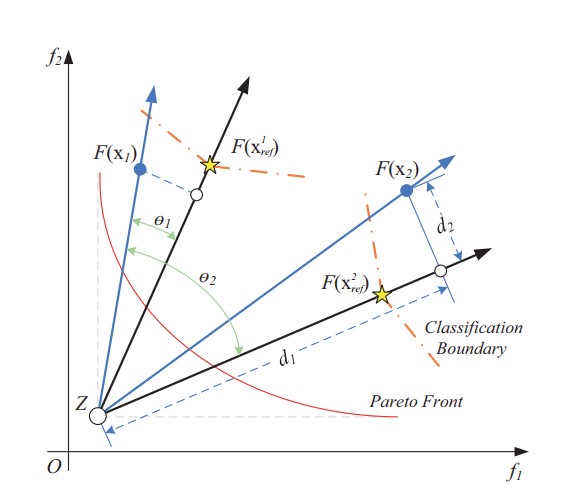
根据PBI方法,当一个解满足
我们就说这个解是非支配的。
根据二分搜索找到PBI的惩罚因子的最适区间,使得分类之后的个体数量尽量接近
这里和传统的支配关系的分割稍有一点不一样,这样可以更好地利用有限的参考点,使得被支配的和非支配的尽量均衡
2、关系模型的构建和辅助选择
- 形成样本对
分别从两个子种群中选取个体形成样本对,因此最多有四种组合,根据PBI的值,它们的标签如下
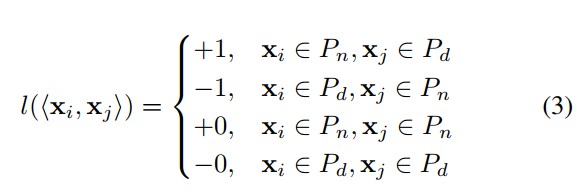
- 平衡训练样本
很明显,而在中需要去除一些个体使得最终
- 网络结构
| 层数 | 描述 | 激活函数 |
|---|---|---|
| 输入层 | 2维 | |
| 隐层 | 3n,2n,n | |
| 输出层 | 3维向量 | 使用one-hot编码得到[0\1,0\1,0\1]表示属于哪一类[+1,0,-1] |
- voting and scoring
根据以下式子计算每个生成的新解和父种群的解x的关系
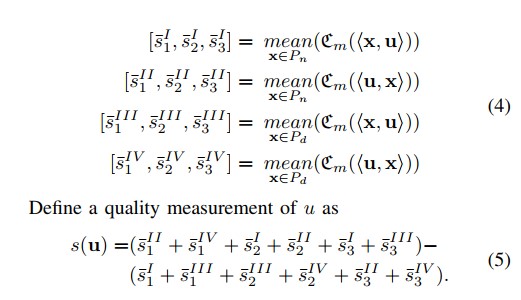
其中表示新生成的解,表示父种群的解,而表示新的个体在子种群中的可信度,4表示该解是非支配的,-4表示该解是被支配的,从而选择优秀的解进入下一代,根据得分的高低选择解,可以容忍模型的部分错误
 wechat
wechat alipay
alipay




