使用高斯模型和模糊均值结合的多目标优化
《Small Data Driven Evolutionary Multi-objective Optimization of Fused Magnesium Furnaces》
abstract
这篇文章是完全面向一个具体工业问题的,一个化工界的熔镁炉(机翻,Fused Magnesium Furnaces),在这个应用背景下,可以得到的只有一小部分离线的,且带有噪声的数据(实验误差),这篇文章干了啥呢?提出一个高斯模型的SAEA方法,基于NSGA-Ⅱ进行种群更新优化,并且自己建立了一个二阶多重回归模型来近似真实的fitness function。
introduction
1、一个低阶的多项式回归可以减少维度灾难和过拟合问题
我的思考
1、为啥建立了一个低阶的多重回归之后还要使用高斯模型来做模型辅助?
它其实相当于做了一个伪on-line的模型。使用一个二阶多项式回归来近似真实的FE,并且在每一代的进化中可以使用这FE来更新数据,训练模型。
因为这个近似的FE其实是一个global的模型,当种群不断进化收敛到局部local的时候,这个模型的效果是很差的,这个FE主要是辅助高斯模型在进化后期也会由于收敛到local这个原因进行重新评估,更新数据。
1、算法框架
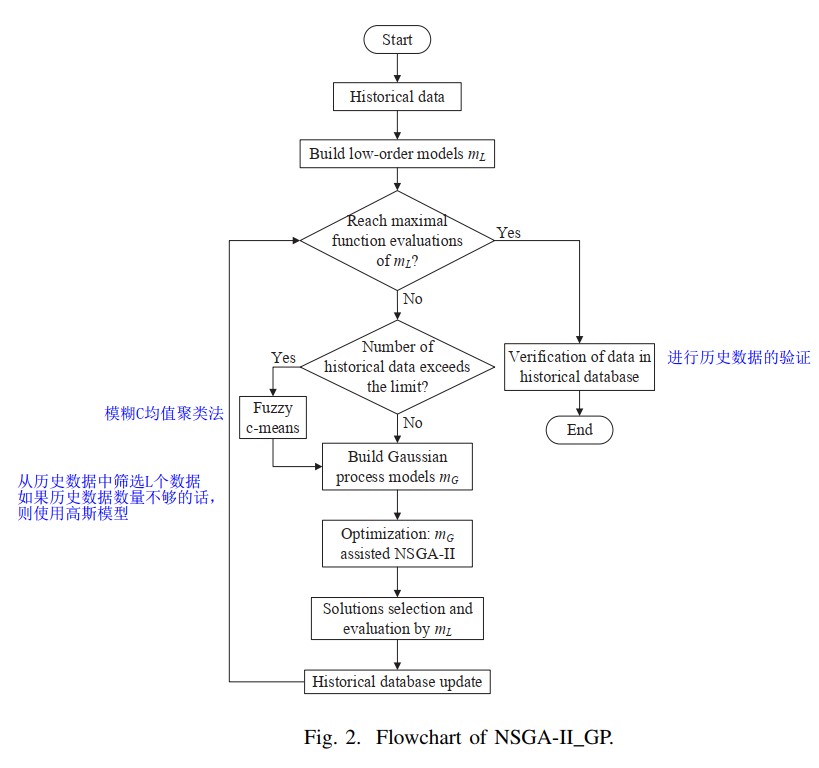
2、细节说明
历史数据的生成
使用LHS采样,但是加入人工噪声(模拟现实情况)对于第j个目标函数值(j=1,…,M)的噪声定义:
这里的rand是一个[-0.1,0.1]之间的随机数
二阶多项式模型
由初始的离线数据进行训练得到。该模型用于计算近似的FE,更新。
对于每一个“(目标,变量)”对建立一个,因此会有个二阶多项式模型(second-order polynomial regression)。其中,M代表目标个数,N代表决策变量的个数
这里选用的是多重回归模型(multiple linear regression)
数据筛选
会不会编故事大概就看这些了(~ ̄▽ ̄)~
并不是用所有的离线数据构建高斯模型,为了减少训练GPM的时间,从历史数据筛选其中的L个数据,如果历史数据不够,那么使用高斯模型生成。
主要是small data嘛,所以数据的量不能太多。
这里选用了模糊c-均值聚类方法,详见《Expensive multiobjective optimization by MOEA/D with Gaussian Process Model》
高斯模型(Guassion process model GPM)
使用被选择的数据对每一个目标建立一个高斯模型,共建立M个GPM,计算相关的expected improvement指标
优化和选择
使用GPM辅助NSGA-Ⅱ,生成新解,构成非支配集,并挑选子代中EI最大的个体保留。从解中选择K个,这些解将会使用再次评估,并入历史数据中。
为了保持解分布的多样性,这里使用以作为阈值,以欧拉距离作为定义的K-聚类的方法,在每一类里均进行数据筛选(data screen)
解的验证和PF的生成
当达到循环结束条件之后,需要将目前的所有历史数据使用真实的目标函数计算估值,非支配的解会直接作为PF的点的近似,而没有真实评估函数可以使用的非主导的性能指标的解则会直接被输出。
3、相关参数说明
| 参数名称 | 参数的值 |
|---|---|
| 种群大小 | 50 |
| 迭代次数 | 50 |
| 250 | |
| 重新评估的解的个数(K) | 5 |
以下是NSGA-Ⅱ的参数设置,参考《A Fast and Elitist Multiobjective Genetic Algorithm:NSGA-II》
| 参数名称 | 参数的值 |
|---|---|
| 交叉率 | 0.9 |
| 变异率 | |
| 种群进化代数 | 250 |
 wechat
wechat alipay
alipay




